We were noticed that our workshop proposal was accepted! We are excited to organize the Context and Compositionality in Biological and Artificial Neural Systems next December at NeurIPS 2019, Vancouver, Canada.
During the workshop we will explore advances in context in language processing and their relationship with compositionality from the different angles of Neuroscience, Linguistics/NLP, and Machine Learning. Therefore, we invite researchers in these and subjecent fields to submit their work until September 18th (11:59pm PT). Check the Call for Papers for more information.
We are looking forward to your interesting contributions and discussions!
The past year, I have been steering my research to a new fascinating topic: language processing and the brain. Together with Prof. Alex Huth and his PhD student Shailee Jain, we are exploring how the brain processes and utilizes context for language understanding. We come up with the idea to extend our internal discussions to a much broader community that includes researchers from Neuroscience, Linguistics, and Machine Learning. One of the best places where researchers from all these fields congregate is at the NeurIPS conference.
Therefore, we embarked in recruiting an amazing group of people that is both interested in the topic and would love to work together to organize such workshop. A few emails and Emma Strubell, Leila Wehbe, Chris Honey, Tal Linzen, Kyunghyun Cho, and Alan Yuille joined us to the organization. Amazing people and several meetings later, and we submitted our NeurIPS workshop proposal. Let’s see how it goes!
In the past few months, I’ve been collaborating with researchers from the Turk-Browne Lab at Yale University. Their ongoing work is about learning the origins of cognition in the human brain. Equipped with fMRI scanners, they scan kids to analyze their cognitive skills at different ages. Their proposal is simple but quite challenging. The challenges start by recruiting families, making sure they are safe and comfortable during the experiments, developing tasks that are suitable for kids of very young ages, and overcoming the data challenges. In particular, the latter requires to rethink machine learning methods that neuroscientists typically use for analyzing data of experiments with adults. The brain develops fast at these ages, and changes are to be expected over time.
Symmetric matrices are very common in many fields. For example, they are used in Kernel Machines to maintain pairwise kernel functions, while in computer vision they represent pairwise distances between points. When a dataset contains ten thousands or more points, these symmetric matrices do not fit in memory and may be too expensive to compute. Existing alternatives suggest to approximate this matrix using a low-rank approximation. Nyström is a very powerful method that samples a subset of the data points and uses them to approximate the matrix. Many research has centered around theory, sampling schemes, and accuracy improvements. However, the method suffers from some practical limitations: it may become unstable when the matrix is not positive semidefinite, and when applied to millions of data points the memory requirements growth, limiting the accuracy of the method.
With Professor Alex Huth, we developed a new method to approximate symmetric matrices that overcomes these limitations. We dubbed our method biharmonic matrix approximation (BHA). Assuming the data points reside in a manifold, BHA samples a subset of data points and interpolates the manifold from this subset using Biharmonic interpolation. The method computes the symmetric matrix of this sampled subset and utilizes the interpolation to approximate the results to the other points. This means of approximation avoids numerical instabilities that exists in other methods. Moreover, the interpolation construction of BHA assigns higher weights to nearby sampled point than to those farther away. From this observation, we construct a sparse version of BHA that reduces the memory consumption enabling approximation of millions of data points and similar accuracy.
The figure depicts the weights for the black vertex in the red zone. The weights are over all the other vertices on the mesh. Red symbolizes positive values, blue negative values and white a near-zero value. This weights represent a column of the interpolation operator of BHA.
A few days ago, our paper “A Semi-supervised Method for Multi-Subject fMRI Functional Alignment” was accepted to the IEEE International Conference on Acoustics, Speech and Signal Processing that will be held next March in New Orleans, Louisiana, USA. This work presents an extension to the original Shared Response Model (SRM), an unsupervised method for multi-subject functional alignment of fMRI data. Using a semi-supervised approach, we show how to train SRM taking into consideration data from a supervised task (multi-label classification). In this way, we need almost half the number of unlabeled samples to achieve the same accuracy level, or achieve higher accuracy with the same number of unlabeled samples.
The method extends the deterministic SRM formulation with a Multinomial Logistic Regression penalty. The semi-supervised SRM inherits the characteristics of the SRM problem, defining a non-convex optimization problem. We solve it using a block-coordinate descent approach, where each block is an unknown matrix. We show similarities to the SRM and MLR, and note that finding the mappings requires to solve an optimization problem in the Stiefel manifold. While this has an closed-form in the SRM case, in the SS-SRM this requires general techniques to solve it. We use the excellent pymanopt package that allowed us to implement a solution for python. Also, the source code of SS-SRM has been published as part of the Brain Imaging Analysis Kit (BrainIAK).
Neuroscientist is the science of learning how the brain works and understanding, among other things, how the brain stores and processes all the information that is received from the world around it. Several imaging techniques have been developed in recent years that allow neuroscientists to peek inside the human brain. The most important step on this direction is the functional Magnetic Resonance Imaging, or fMRI, that captures the brain activation indirectly from the blood oxygenation levels. With fMRI we can capture a full brain scan every few seconds. Such scans are volumes of the brain comprised of thousands-to-millions of voxels. Processing of these scans is done usually with machine learning algorithms and statistic tools.
Storing a subject information in memory is possible with today servers. However, doing it with a tens of them is very limiting. Therefore, storing all this data requires multiple machines to be stored at once. Moreover, using multi-subject datasets helps to improve the statistical capacity of the machine learning methods that are incorporated in the neuroscience experiments. In a recent work from our research group, we published a manuscript describing how we scale out two factor analysis methods (for dimensionality reduction). We show that is possible to use hundreds to thousands of subjects for neuroscience studies.
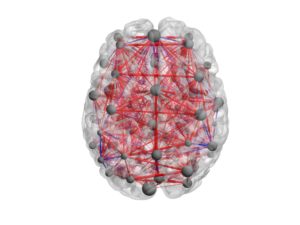
The first method is called the Shared Response Model (SRM). The SRM computes a series of mappings from the subjects’ volumes to a shared subspace. These mappings improve the predictability of the model and help increase the accuracy of subsequent machine learning algorithms used in a study. The second method, dubbed Hierarchical Topographic Analysis (HTFA), is a model that abstracts the brain activity with hubs (spheres) of activity and dynamic interlinks across them. HTFA helps with the interpretation of the brain dynamics, outputting networks as the one in the figure below. For both methods, we present algorithms that can run distributively and process a 1000-subject dataset. Our work “Enabling Factor Analysis on Thousand-Subject Neuroimaging Datasets” aims to push the limits of what neuroscientist can do with multi-subject data and enable them to propose experiments that were unthinkable before.
I added the link to the paper “A Multilevel Framework for Sparse Optimization With Application to Inverse Covariance Estimation and Logistic Regression” soon to appear in SIAM Scientific Computing (SISC) journal. The paper describes a method that accelerates sparse optimization methods that use L1 regularization to achieve sparse solution. We show how to apply this method to the sparse inverse covariance method (also known as GLASSO) and the L1-regularized logistic regression.
Thanks to some requests that I received lately, I decided to upload source code for the work “On MAP and MMSE Estimators for the Co-sparse Analysis Model”. Hope that this could be useful for more researchers. The code is in github publicly available. Please, I would like to hear you back from everyone using it.
At the beginning of November our “A Multilevel Acceleration for l1-regularized Logistic Regression” work on how to accelerate the L1-regularized logistic regression problem was accepted to the Optimization workshop at NIPS 2015. Last week, I presented the work in the Optimization workshop at NIPS 2015. This year the Optimization workshop grew a lot, having about 50 posters in several optimization topics.
This work was a collaboration between Earn Treister (Univ. Of British Columbia) and myself (Intel Labs).
A recent paper “Clutter Mitigation in Echocardiography using Sparse Signal Separation” has been accepted for publication. The article discuss how to apply a sparsity prior to separate clutter from tissue in cardiac ultrasound images. The suggested method uses an adaptive dictionary learned from the patient data using K-SVD. The main challenge of this work was to separate the tissue and the clutter atoms as the trained dictionary includes atoms from both signals. A good separation of the dictionary yields a state-of-the-art clutter mitigation. We tested the robustness of the method and demonstrated its capabilities in real-world sequences.
In incoming weeks, the article will be published in the International Journal on Biomedical Imaging and this post will be updated once the paper is online.