Neuroscientist is the science of learning how the brain works and understanding, among other things, how the brain stores and processes all the information that is received from the world around it. Several imaging techniques have been developed in recent years that allow neuroscientists to peek inside the human brain. The most important step on this direction is the functional Magnetic Resonance Imaging, or fMRI, that captures the brain activation indirectly from the blood oxygenation levels. With fMRI we can capture a full brain scan every few seconds. Such scans are volumes of the brain comprised of thousands-to-millions of voxels. Processing of these scans is done usually with machine learning algorithms and statistic tools.
Storing a subject information in memory is possible with today servers. However, doing it with a tens of them is very limiting. Therefore, storing all this data requires multiple machines to be stored at once. Moreover, using multi-subject datasets helps to improve the statistical capacity of the machine learning methods that are incorporated in the neuroscience experiments. In a recent work from our research group, we published a manuscript describing how we scale out two factor analysis methods (for dimensionality reduction). We show that is possible to use hundreds to thousands of subjects for neuroscience studies.
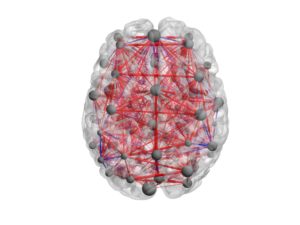
The first method is called the Shared Response Model (SRM). The SRM computes a series of mappings from the subjects’ volumes to a shared subspace. These mappings improve the predictability of the model and help increase the accuracy of subsequent machine learning algorithms used in a study. The second method, dubbed Hierarchical Topographic Analysis (HTFA), is a model that abstracts the brain activity with hubs (spheres) of activity and dynamic interlinks across them. HTFA helps with the interpretation of the brain dynamics, outputting networks as the one in the figure below. For both methods, we present algorithms that can run distributively and process a 1000-subject dataset. Our work “Enabling Factor Analysis on Thousand-Subject Neuroimaging Datasets” aims to push the limits of what neuroscientist can do with multi-subject data and enable them to propose experiments that were unthinkable before.